Kernels for categorical variables have emerged as a pivotal concept in the realm of data science and machine learning. With the rapid growth of data and the increasing complexity of datasets, it's essential to harness effective methods that can handle categorical data efficiently. Unlike numerical data, categorical variables present unique challenges, demanding specialized kernels to ensure accurate classification and prediction.
The significance of utilizing kernels for categorical variables lies in their ability to transform non-numeric data into a format that machine learning algorithms can effectively process. Traditional kernels, designed primarily for continuous variables, often fall short when faced with categorical data. Therefore, researchers and practitioners are continually exploring innovative approaches to develop kernels that can manage these variables, enhancing the performance of various machine learning models.
In this article, we will delve into the fundamental concepts surrounding kernels for categorical variables, discussing their applications, advantages, and the future of this exciting area in data science. By understanding how these kernels work, you can leverage them to improve your classification tasks and gain deeper insights from your datasets.
What Are Kernels for Categorical Variables?
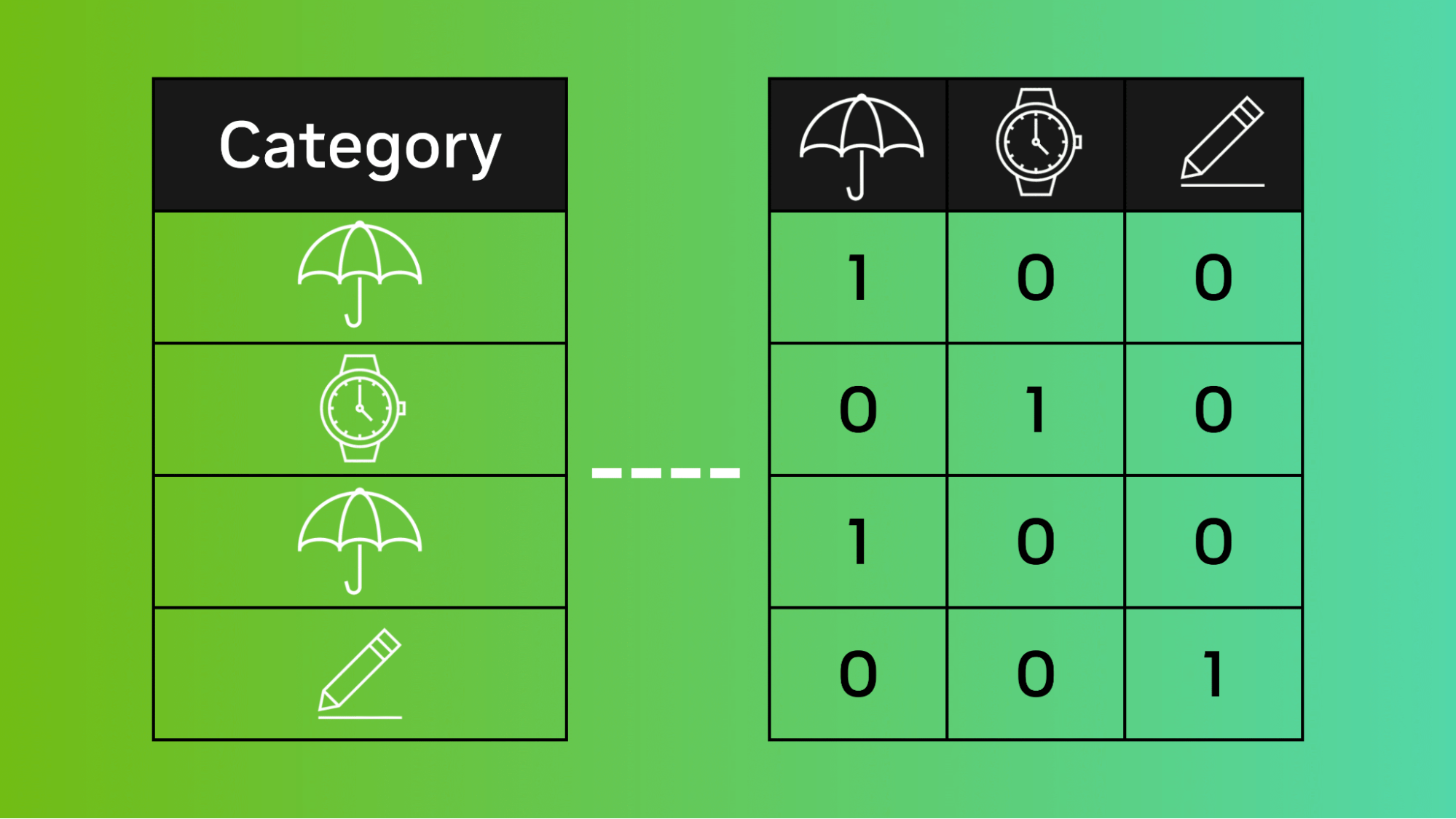
Kernels for categorical variables are functions that enable the measurement of similarity between categorical data points. Unlike traditional kernels, which primarily focus on numerical attributes, these specialized kernels allow for the effective analysis of data where attributes are labels or categories. Some common examples of categorical data include gender, color, and product types.
How Do Kernels for Categorical Variables Work?
Understanding how kernels for categorical variables function involves grasping the concept of similarity measures. These kernels often utilize techniques such as:
- Hamming Distance: A method that counts the number of positions at which two categorical variables differ.
- One-Hot Encoding: A technique that transforms categorical variables into a binary matrix representation.
- CatBoost and Other Specialized Algorithms: Machine learning algorithms designed to handle categorical variables directly.
Why Are Kernels for Categorical Variables Important?
The importance of kernels for categorical variables cannot be overstated. As datasets continue to grow in complexity, the ability to accurately model and predict outcomes based on categorical data becomes increasingly vital. Here are some reasons why these kernels are essential:
- Enhanced Predictive Performance: By effectively handling categorical data, kernels can improve the accuracy of predictions.
- Better Interpretability: Kernels designed for categorical variables can provide clearer insights into the relationships between different categories.
- Improved Model Robustness: Specialized kernels can lead to more robust models that generalize better to unseen data.
What Are Some Applications of Kernels for Categorical Variables?
Kernels for categorical variables have a broad range of applications across various fields. Some noteworthy examples include:
- Marketing Analytics: Analyzing customer preferences based on demographic data.
- Medical Research: Classifying patient data according to categorical health conditions.
- Social Media Analysis: Examining user-generated content based on categorical features such as hashtags and categories.
How Do You Implement Kernels for Categorical Variables?
Implementing kernels for categorical variables requires a systematic approach. Here are the general steps to follow:
- Data Preprocessing: Clean and transform your categorical data into an appropriate format.
- Select Kernel Function: Choose the appropriate kernel function based on your dataset.
- Model Training: Train your machine learning model using the selected kernel.
- Evaluation: Assess the model’s performance using metrics such as accuracy and F1-score.
What Are the Challenges of Using Kernels for Categorical Variables?
Despite their advantages, kernels for categorical variables also come with challenges. These may include:
- High Cardinality: Categories with a large number of unique values can complicate the kernel calculation.
- Data Sparsity: Sparse data can lead to ineffective similarity measures.
- Computational Complexity: Some kernel functions may require substantial computational resources.
What Is the Future of Kernels for Categorical Variables?
The future of kernels for categorical variables looks promising, with ongoing research focused on improving their efficiency and effectiveness. Innovations in deep learning and neural networks are expected to further enhance the capabilities of these kernels, allowing for better integration of categorical data in various applications. As machine learning continues to evolve, the importance of developing robust kernels tailored for categorical variables will only grow.
Conclusion: Embracing Kernels for Categorical Variables
In conclusion, kernels for categorical variables represent a crucial advancement in the field of data science. By effectively managing categorical data, these specialized kernels pave the way for improved predictive models and insightful analyses. As we continue to explore the complexities of data, embracing and understanding kernels for categorical variables will undoubtedly enhance our ability to extract meaningful information and make informed decisions.
You Might Also Like
Exploring The Legacy Of The United States Postage One Cent StampCream Dory: The Delicate Delight Of The Sea
Exploring The World Of Fake Privacy Trees: A Unique Solution For Outdoor Privacy
Discovering The Mouthwatering Delight Of Hardee's Double Cheeseburger
The Ultimate Guide To Choosing The Best Fertilizer For Pepper Plants
Article Recommendations
- Cholea Surreal An Insightful Guide To Its Mystique And Significance
- Is Elon Musk The Antichrist A Deep Dive Into The Controversial Debate
- Linda De Sousa Abreu A Comprehensive Biography And Impact On Society